Our StreamSets Data Integration Patterns
With our continuous and expanding use of StreamSets as our data integration component we started formalizing some emerging patterns that allowed us to:
Simplify maintenance
Avoid downtimes
Take advantage of the use of Kafka, HAproxy and pipeline replication to scale integrations with large data volumes or complex transformations
What follows is a list of some of our most used patterns.
Logical High-Level Data Integration Pattern
As a general rule, we divide each integration into 3 stages that can contain 3 or more pipelines.
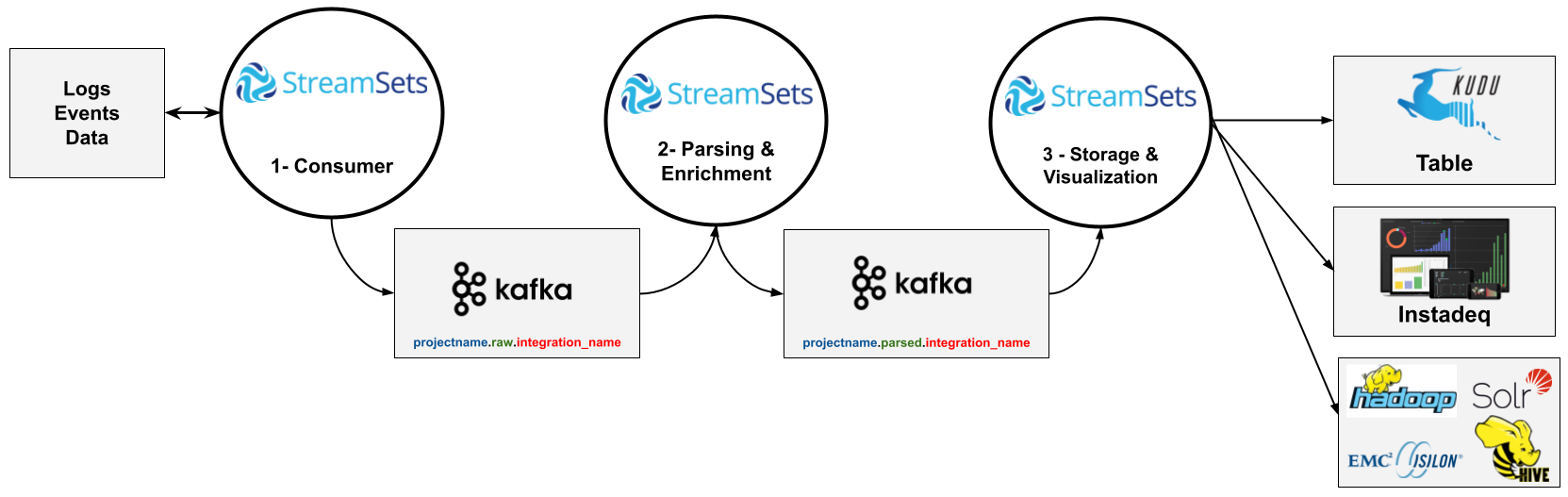
The advantages for this approach are:
Stages isolation allows process changes at a specific stage without affecting the others.
Kafka in the middle assures that if a parser or store is down, data continues to be consumed and stored in Kafka for 7 days.
Kafka also allows parallel processing with replicated pipelines.
The parsed logs pushed to Kafka can be accessed immediately by other tools such as Flink Streaming, KSQL or Machine Learning containers without replicating the rules applied in the Streamsets pipelines.
We can have pipelines running and consuming logs in computers outside our cluster and pushing the data to Kafka. Later the parsing and storage is centralized in the cluster.
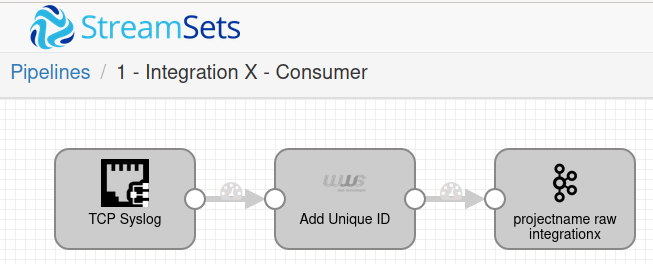
Stage 1 - Consumer Pipeline
A StreamSets pipeline consumes raw data and pushes it into a Kafka Topic with the name projectname.raw.integration. For example projectx.raw.weblogic
This allows us to modify, stop and restart the Parse and Store pipelines without losing the data generated during maintenance windows
This pipeline is not needed for agents that write directly to kafka
For some specific cases, the same pipeline or another one writes the data to HDFS or external storage that needs the raw data. Mainly sources required for audits.
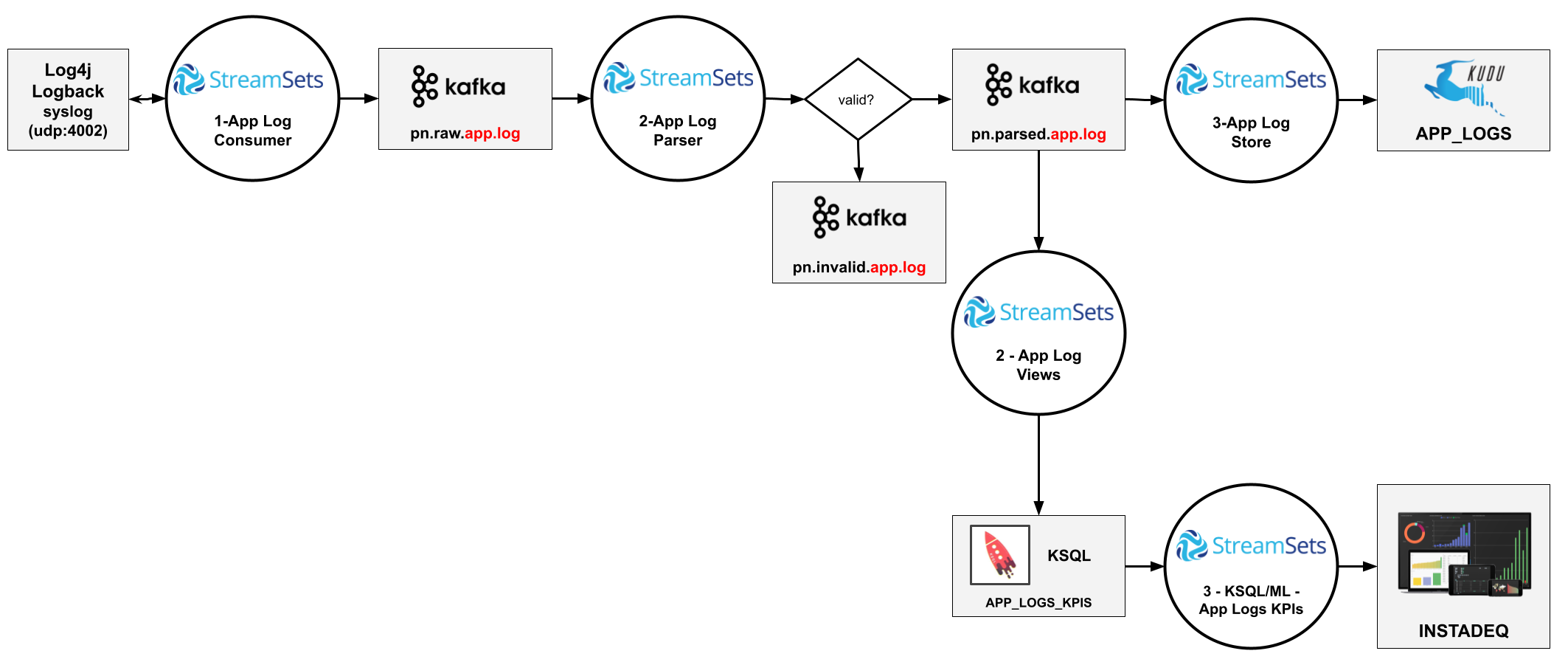
Stage 2 - Parse & Enrichment Pipeline
A second pipeline consumes the raw data from the raw topic, parses and enriches the log and stores the new data in a new topic: projectname.parsed.integration
The most common transformations are:
Parse log pattern using Log Parser.
Remove unnecessary fields with Field Remover.
Rename or change a field's case using Field Renamer.
Generate new fields using Expression Evaluators.
-
Enrichment using Redis Lookup or Apache Solr as key value stores. For example:
Add an environment field (prod, stage, qa, dev) using the hostname as key
Add company details using their tax identification number
IP geolocation lookup
Convert date to UTC or string to numbers using Field Type Converter.
Discard records or route them to different Kafka topics using Stream Selector.
Flatten fields with Field Flattener.
Some complex business rules written in Jython.
Generate fields year, month, day for partitioning in Kudu.
Generate Globally Unique Identifier (GUID / UUID).
Parse date fields.
The following is our “2 - Apache Access - Parser” pipeline:
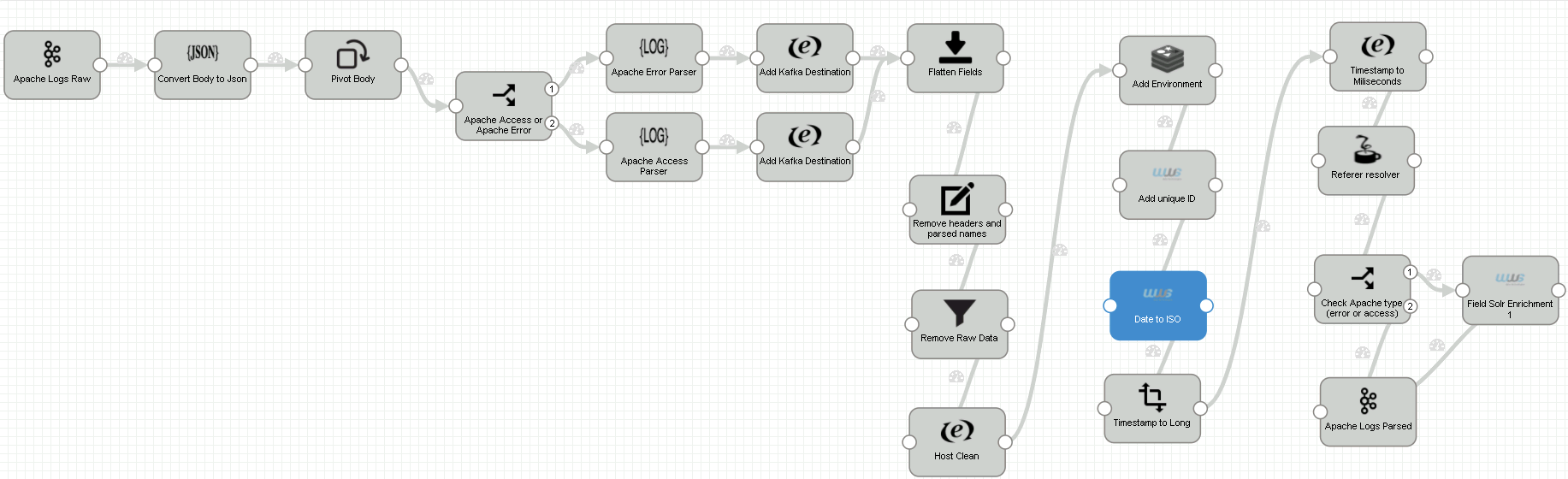
Steps:
1. Consumes logs from the "raw" topic
2. Converts HTTP body to Json
3. Pivot Body fields to the root of the Record
4. Route apache error and apache access to different paths
1.1. Parse apache error
1.2. Add Kafka destination: parsed.apache_error topic
2.1. Parse apache access
2.2. Add Kafka destination: parsed.apache_access topic
5. Flatten fields
6. Remove headers and parsed names
7. Remove fields with raw data
8. Clean host names (lowercase and remove domain)
9. Solve environment using Redis
10. Add an ID field with an UUID
11. Convert dates to ISO
12. Convert timestamp fields to Long
13. Convert timestamps to milliseconds
14. Resolve apache access refererer
15. For apache access logs, use the IP address to identify geolocation
using Apache Solr
16. Write the log to project_name.parsed.apache_access
or project_name.parsed.apache_error
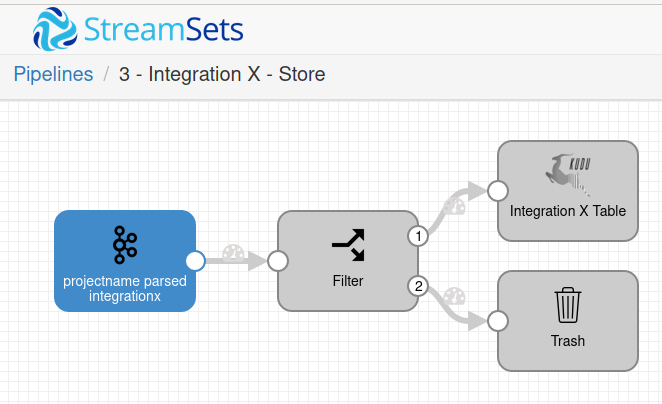
Stage 3 - Storage & Visualization Pipelines
The third pipeline consumes the parsed data from the topic and sends it to:
A Kudu table
HDFS folder
External storage (outside our cluster) such as Oracle databases
NAS storage for historical and backup such as EMC Isilon
External Kafka Brokers (outside our cluster)
Instadeq for live dashboards and data exploration
Sometimes we use a single pipeline in StreamSets but if the destinations have different speeds or if one of them has more errors that provokes pipeline restarts, we use different pipelines for each destination.
We maintain the number 3 for all the pipelines because they all consume the logs from the parsed topics but send them to different destinations:
3- Tomcat Access - Kudu Storage
3- Tomcat Access - HDFS Storage
3- Tomcat Access - Long-Term Isilon Storage
3- Tomcat Access - Instadeq Dashboard
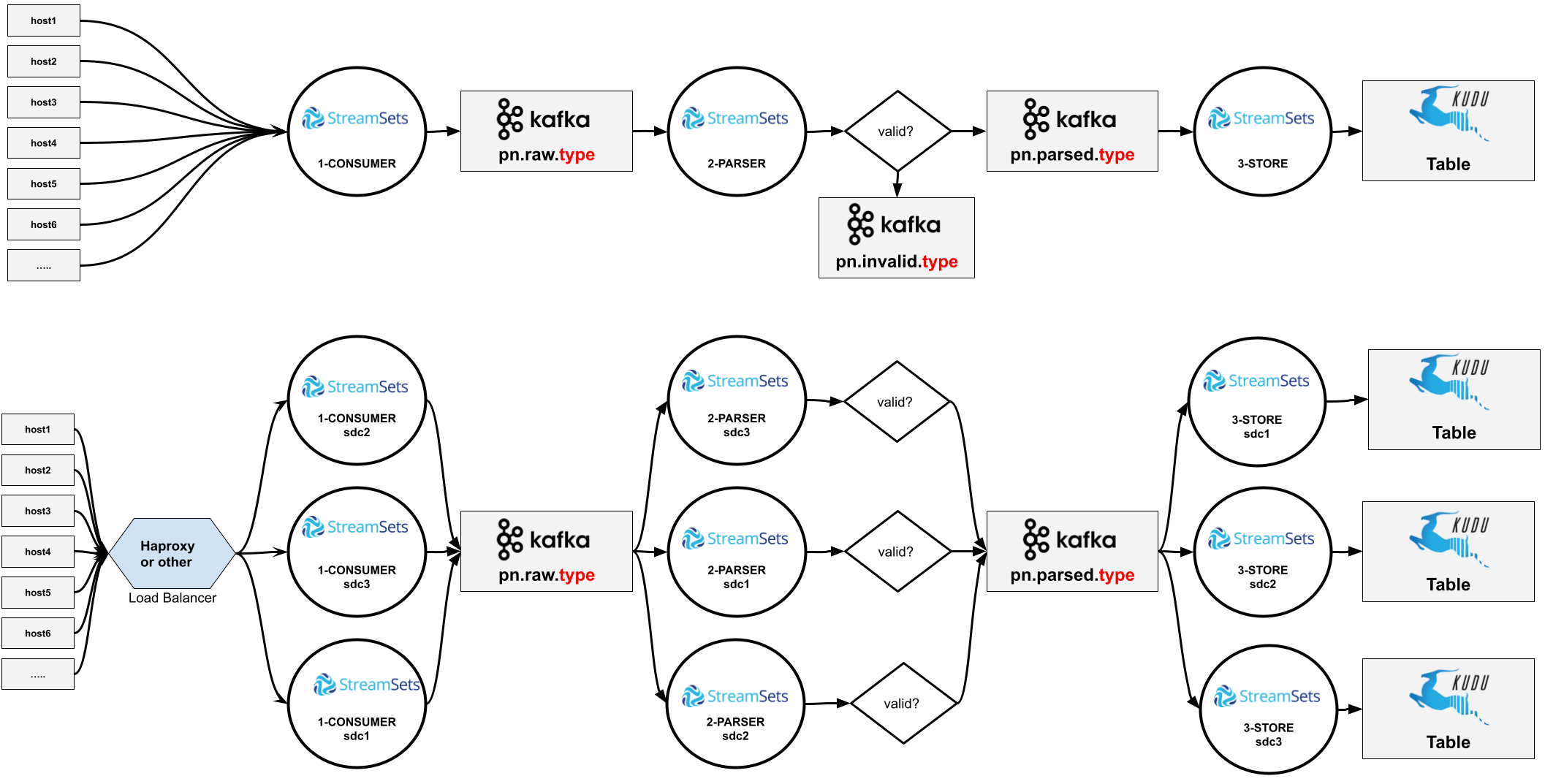
Scaling Pipelines
When we have a pipeline with a high data volume, we scale it with:
HAproxy acting as load balancer
StreamSets pipeline replication
Kafka topic partitioning
For example in two customers we receive Tomcat access logs through HTTP posts and we have the following setup:
HAproxy Load Balancer
We create a new entry in our server running HAproxy: /etc/haproxy/haproxy.cfg
We receive HTTP Requests on port 4005 and forward them to 3 different “1- Tomcat Access - Consumer” StreamSets pipelines running in cluster-host-01, cluster-host-02 and cluster-host-03
frontend tomcat_access bind 0.0.0.0:4005 mode http stats enable stats refresh 10s stats hide-version default_backend tomcat_access_servers tomcat_access_servers balance roundrobin default-server maxconn 20 server sdc1 cluster-host-01:4005 check port 4005 server sdc2 cluster-host-02:4005 check port 4005 server sdc3 cluster-host-03:4005 check port 4005
Kafka: Topic Partitioning
We create projectx.raw.tomcat_access and projectx.parsed.tomcat_access Kafka topics with 3 or more partitions:
/bin/kafka-topics.sh --create \ --zookeeper <hostname>:<port> \ --topic projectx.raw.tomcat_access \ --partitions 3 \ --replication-factor <number-of-replicating-servers> /bin/kafka-topics.sh --create \ --zookeeper <hostname>:<port> \ --topic projectx.parsed.tomcat_access \ --partitions 3 \ --replication-factor <number-of-replicating-servers>
Streamsets: Pipeline Replication
We replicate our pipeline to run in different cluster nodes, each one consuming from one of those partitions.
1- Tomcat Access - Consumer
Three pipeline instances running in three different nodes
Consume logs using a HTTP Server Origin listening on port 4005
Write the raw logs to Kafka using a Kafka Producer Destination
Target Kafka topic: projectx.raw.tomcat_access
2- Tomcat Access - Parser
Three pipeline instances running in three different nodes
Consume raw logs from Kafka using a Kafka Consumer Origin
Source topic: projectx.raw.tomcat_access
Parse, enrich and filter the logs
Write them to Kafka using a Kafka Producer Destination
Target topic: projectx.parsed.tomcat_access
3- Tomcat Access - Storage
Three pipeline instances running in three different nodes
Consume enriched Tomcat access logs from Kafka using a Kafka Consumer Origin
Source Kafka topic: projectx.parsed.tomcat_access
Store them in a Kudu table using a Kudu Destination.
Target Kudu table: projectx.tomcat_access
3- Tomcat Access - Instadeq Dashboard
A single pipeline instance
Consume enriched Tomcat Access logs from the three Kafka partitions using a Kafka Consumer Origin
Source Kafka Topic: projectx.parsed.tomcat_access
Send them to Instadeq using Instadeq webhooks
Examples
Linux logs from RSysLog to a Kudu table using StreamSets for data ingestion and transformation

Java application logs sent to the cluster using log4j or logback, with StreamSets for data ingestion and transformation, KSQL for streaming analytics, Kudu for storage and Instadeq for live dashboards
From Redmine to Instadeq Dashboard using Streamsets: Direct Integration without Kafka or any storage in the middle