Japan's Fifth Generation Computer Systems: Success or Failure?
This post is a summary of content from papers covering the topic, it's mostly quotes from the papers from 1983, 1993 and 1997 with some edition, references to the present and future depend on the paper but should be easy to deduce. See the Sources section at the end.
Introduction
In 1981, the emergence of the government-industry project in Japan known as Fifth Generation Computer Systems (FGCS) was unexpected and dramatic.
The Ministry of International Trade and Industry (MITI) and some of its scientists at Electrotechnical Laboratory (ETL) planned a project of remarkable scope, projecting both technical daring and major impact upon the economy and society.
This project captured the imagination of the Japanese people (e.g. a book in Japanese by Junichiro Uemae recounting its birth was titled The Japanese Dream).
It also captured the attention of the governments and computer industries of the USA and Europe, who were already wary of Japanese takeovers of important industries.
A book by Feigenbaum and McCorduck, The Fifth Generation, was a widely-read manifestation of this concern.
The Japanese plan was grand but it was unrealistic, and was immediately seen to be so by the MITI planners and ETL scientists who took charge of the project.
A revised planning document was issued in May 1982 that set more realistic objectives for the Fifth Generation Project.
Previous Four Generations
First generation: ENIAC, invented in 1946, and others that used vacuum tubes.
Second generation: IBM 1401, introduced in 1959, and others that used transistors.
Third generation: IBM S/360, introduced in 1964, and others that used integrated circuits.
Fourth generation: IBM E Series, introduced in 1979, and others that used very large-scale integrated circuits, VLSI which have massively increased computational capacity but are still based on the Von Neumann architecture and require specific and precise commands to perform a task.
FGCS was conceived as a computer that can infer from an incomplete instruction, by making use of the knowledge it has accumulated in its database.
FGCS was based on an architecture distinct from that of the previous four generations of computers which had been invented by Von Neumann and commercially developed by IBM among others.
The Vision
Increased intelligence and ease of use so that they will be better able to assist man. Input and output using speech, voice, graphics, images and documents, using everyday language, store knowledge to practical use and to the ability to learn and reason.
To lessen the burden of software generation in order that a high level requirements specification is sufficient for automatic processing, so that program verification is possible thus increasing the reliability of software. Also the programming environment has to be improved while it should also be possible to use existing software assets.
To improve overall functions and performance to meet social needs. The construction of light, compact, high-speed, large capacity computers which are able to meet increased diversification and adaptability, which are highly reliable and offer sophisticated functions.
Objectives
The objective of this project is to realise new computer systems to meet the anticipated requirements of the 1990s.
Everybody will be using computers in daily life without thinking anything of it. For this objective, an environment will have to be created in which a man and a computer find it easy to communicate freely using multiple information media, such as speech, text, and graphs.
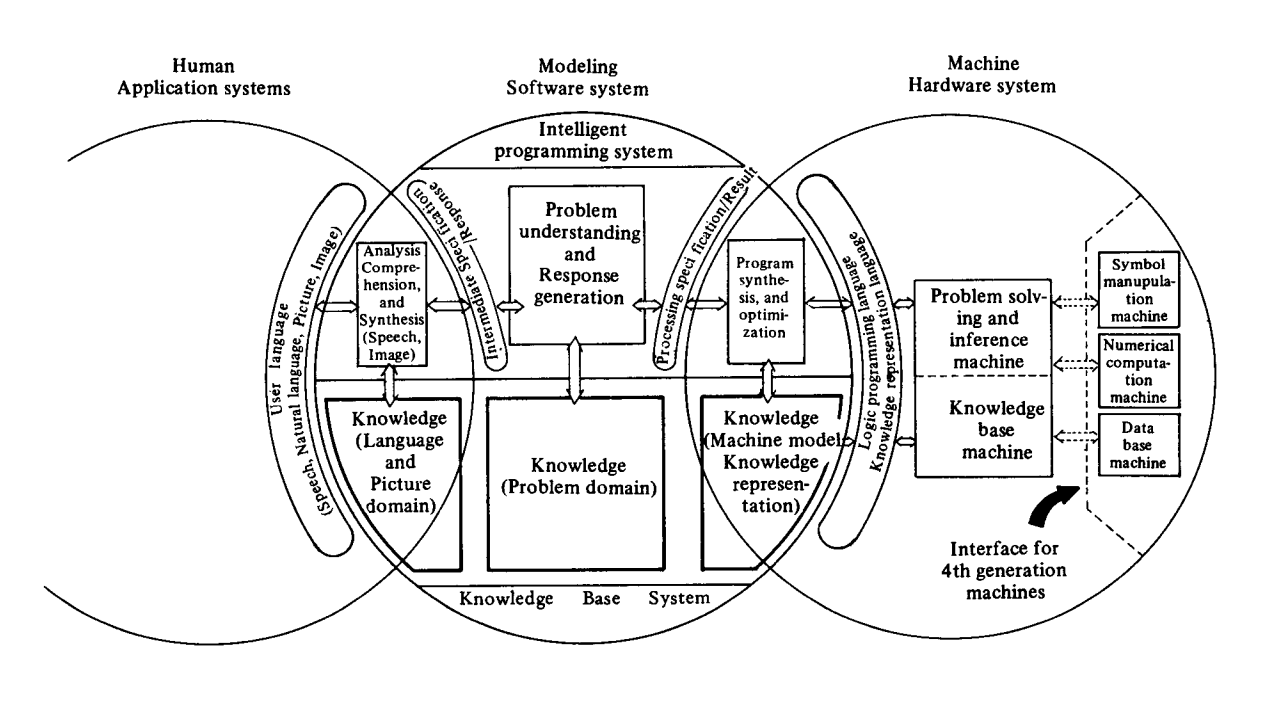
The functions of FGCSs may be roughly classified as follows:
Problem-solving and inference
Knowledge-base management
Intelligent interface
The intelligent interface function will have to be capable of handling man/machine communication in natural languages, speeches, graphs, and images so that information can be exchanged in a way natural to a man.
There will also be research into and development of dedicated hardware processors and high-performance interface equipment for efficiently executing processing of speech, graph, and image data.
Several basic application systems will be developed with the intention of demonstrating the usefulness of the FGCS and the system evaluation. These are machine translation systems, consultation systems, intelligent programming systems and an intelligent VLSI-CAD system.
The key technologies for the Fifth Generation Computer System seem to be:
VLSI architecture
Parallel processing such as data flow control
Logic programming
Knowledge base based on relational database
Applied artificial intelligence and pattern processing
Project Requirements
Realisation of basic mechanisms for inference, association, and learning in hardware, making them the core functions of the Fifth Generation computers.
Preparation of basic artificial intelligence software in order to fully utllise the above functions.
Advantageous use of pattern recognition and artificial intelligence research achievements, in order to realise man/machine interfaces that are natural to man.
Realisation of support systems for resolving the 'software crisis' and enhancing software production.
It will be necessary to develop high performance inference machines capable of serving as core processors that use rules and assertions to process knowledge information.
Existing artificial intelligence technology has been developed to be based primarily on LISP. However, it seems more appropriate to employ a Prolog-like logic programming language as the interface between software and hardware due to the following considerations: the introduction of VLSI technology made possible the implementation of high level functions in hardware; in order to perform parallel processing, it will be necessary to adopt new languages suitable for parallel processing; such languages will have to have a strong affinity with relational data models.
Research and development will be conducted for a parallel processing hardware architecture intended for parallel processing of new knowledge bases, and which is based on a relational database machine that includes a high-performance hierarchical memory system, and a mechanism for parallel relational operations and knowledge operations.
The knowledge base system is expected to be implemented on a relational database machine which has some knowledge base facilities in the Fifth Generation Computer System, because the relational data model has a strong affinity with logic programming.
Relational calculus has a close relation with the first order predicate logic. Relational algebra has the same ability as relational calculus in the description of a query. These are reasons for considering a relational algebra machine as the prime candidate for a knowledge base machine.
Risks
There is no precedent for this innovative and large-scale research and development anywhere in the world. We will therefore be obliged to move toward the target systems through a lengthy process of trial and error, producing many original ideas along the way.
Timeline / Plan
(1982-1984) Initial Stage
During the initial stage, research was conducted on the basic technologies for FGCS. The technologies developed included:
ESP (extended self-contained Prolog), a sequential logic-programming language based on Prolog.
PSI (personal sequential inference machine), the world's first sequential inference computer to incorporate a hardware inference engine.
SIMPOS (sequential inference machine programming and operating system), the world's first logic-programming-language-based operating system written with ESP for the PSI.
GHC (guarded horn clauses), a new parallel-logic language for the implementation of parallel inference.
(1985-1988) Intermediate Stage
During the intermediate stage, research was done on the algorithms needed for implementation of the subsystems that would form the basis of FGCS and on the basic architecture of the new computer.
Furthermore, on the basis of this research, small and medium-sized subsystems were developed. The technologies developed included:
KL1, a logic language for parallel inference.
PIMOS (parallel inference machine operating system), a parallel-machine operating system based on the use of KL1 (kernel horn clauses 1).
KAPPA (knowledge application oriented advanced database and knowledge base management system), a knowledge-base management system capable of handling large amounts of complex knowledge.
MultiPSI, an experimental parallel inference machine consisting of 64 element processors linked together in the form of a two-dimensional lattice.
(1989-1992) Final Stage
During the final stage, the object was to put together a prototype fifth generation computer based on the technologies developed during the two preceding stages. The project team developed a number of additional features including:
PIM (parallel inference machine), a parallel inference computer consisting of 1000 linked element processors.
Improvement of PIMOS.
KAPPA-p, a parallel data-management system. For the knowledge programming system the team also developed.
Interactive interface technology.
Problem-solving programming technology.
Knowledge-base creation technology.
To test the prototype system, the team also carried out research into the integration and application of parallel programming technology.
several application software programs were developed to run on the PIM.
(1993-1994) Wrap Up
The project continued on a more limited scale during 1993 and 1994.
In addition to follow-up research on, say, a new KL1 programming environment (called KL1C) on sequential and parallel UNIX-based machines, many efforts were made to disseminate FGCS technologies, for instance, to distribute free ICOT software and to disclose technical data on the Internet.
Why not a Generation Evolution?
For computers to be employed at numerous application levels in the 1990s, they must evolve from machines centered around numerical computations to machines that can assess the meaning of information and understand the problems to be solved.
Non-numeric data such as sentences, speeches, graphs, and images will be used in tremendous volume compared to numerical data.
Computers are expected to deal with non-numeric data mainly in future applications. However, present computers have much less capability in non-numeric data processing than in numeric data processing.
The key factors leading to the necessity for rethinking the conventional computer design philosophy just described include the following:
Device speeds are approaching the limit imposed by the speed of light.
The emergence of VLSI reduces hardware costs substantially, and an environment permitting the use of as much hardware as is required will shortly be feasible.
To take advantage of the effect of VLSI mass production, it will be necessary to pursue parallel processing.
Current computers have extremely poor performance in basic functions for processing speeches, texts, graphs, images and other nonnumerical data, and for artificial intelligence type processing such as inference, association, and learning.
The research and development targets of the FGCS are such core functions of knowledge information processing as problem-solving and inference systems and knowledge-base systems that cannot be handled within the framework of conventional computer systems.
Results
With the Fourth Conference on Fifth Generation Computer Systems, held June 1-5, 1992 in Tokyo, Japan, an era came to an end.
This section quotes different people analyzing the results, it won't be fully consistent
Since then ten years have passed in which ICOT grew to about 100 researchers and spent about 54 billion Yen, that is some 450 million US$. In these ten years a large variety of machines have been built ranging from the special purpose PSI machine, that is a personal sequential inference machine, to several constellations of processors and memory ranging from 16 to 512 processing elements together forming the PIM family, that is the Parallel Inference Machine.
Overreaction
Some people overreacted and spoke even of a technological war. Today some people again overreact. As they see that their fears have not materialized, they regard the project as a failure.
Evaluation
Scientific:
✅ Hardware: use of parallelism
✅ Software: use of logic programming
-
✅ Applications
❌ No natural language, no pattern recognition
❌ Break-through in architecture
❌ Break-through in software
Economic:
✅ Impact on Japanese researchers
❌ Impact on Japanese hardware makers
Social:
-
✅ International scientific reputation
❌ But no solution to social problems in Japan
Positive
ICOT has shown the ability of Japan to innovate in computer architectures.
The ICOT architectures' peak parallel performance is within the range of the original performance goals.
The PIMs represent an opportunity to study tradeoffs in parallel symbolic computing which does not exist elsewhere.
KL1 is an interesting model for parallel symbolic computation, but one which is unlikely to capture the imagination of US researchers.
PIMOS has interesting ideas on control of distribution and communication which US researchers should evaluate seriously.
ICOT has been one of the few research centers pursuing parallel symbolic computations.
ICOT has been the only center with a sustained effort in this area.
ICOT has shown significant (i.e. nearly linear) acceleration of non regular computations (i.e. those not suitable for data parallelism of vectorized pipelining).
ICOT created a positive aura for AI, Knowledge Based Systems, and innovative computer architectures. Some of the best young researchers have entered these fields because of the existence of ICOT.
Negative
ICOT has done little to advance the state of knowledge based systems, or Artificial Intelligence per se.
ICOT's goals in the area of natural language were either dropped or spun out to EDR.
Other areas of advanced man machine interfacing were dropped.
Research on Very Large Knowledge bases were substantially dropped.
ICOT's efforts have had little to do with commercial application of AI technology. Choice of language was critical.
ICOT's architectures have been commercial failures. Required both a switch in programming model and the purchase of cost ineffective hardware.
ICOT hardware has lagged behind US hardware innovation (e.g. the MIT Lisp Machine and its descendants and the MIT Connection Machine and its descendants).
Application systems of the scale described in the original goals have not been developed (yet).
Very little work on knowledge acquisition.
The early documents discuss the management of very large knowledge bases, of large scale natural language understanding and image understanding with a strong emphasis on knowledge acquisition and learning. Each of these directions seems to have been either dropped, relegated to secondary status, absorbed into the work on parallelism or transferred to other research initiatives.
The ICOT work has tended to be a world closed in upon itself. In both the sequential and parallel phases of their research, there has been a new language developed which is only available on the ICOT hardware. Furthermore, the ICOT hardware has been experimental and not cost effective. This has prevented the ICOT technology from having any impact on or enrichment from the practical work.
Changes
It is remarkable how little attention is given to the notion of parallel processing, while this notion turned out to be of such great importance for the whole project.
First, in my opinion the original goal of the FGCS project changed its emphasis from what has been described above as primarily a knowledge information processing system, KIPS, with very strong capabilities in man-machine interaction, such as natural language processing, into the following:
A computer system which is:
Easy to use intellectually
Fast in solving complex problems
In combining the two ideals:
Efficient for the mind
Efficient for the machine
The intellectual process of translating a problem into the solution of that problem should be simple. By exploiting sophisticated (parallel processing) techniques the computer should be fast.
Research Impact
Japan has indeed proved that it has the vision to take a lead for the rest of the world.
They acted wisely and offered the results to the international public for free use, thus acting as a leader to the benefit of mankind and not only for its own self-interest.
One of the major results and successes of the FGCS project is its effect on the infrastructure of Japanese research and development in information technology.
The technical achievements of ICOT are impressive. Given the novelty of the approaches, the lack of background, the difficulties to be solved, the amount of work done which has delivered something of interest is purely amazing; this is true in hardware as well as in software.
The fulfillment of the vision, should I say working on the "grand plan" and bringing benefits to the society, is definitely not at the level that some people anticipated when the project was launched. This is not, to me, a surprise at all, i.e. I have never believed that very significant parts of this grand plan could be successfully tackled.
Overall, the project has had a major scientific impact, in furthering knowledge throughout the world of how to build advanced computing systems.
I agree that the international impact of the project was not as large as one hoped for in the beginning. I think all of us who believed in the direction taken by the project, i.e. developing integrated parallel computer systems based on logic programming, hoped that by the end of the 10 years' period the superiority of the logic programming approach will be demonstrated beyond doubt, and that commercial applications of this technology will be well on their way. Unfortunately, this has not been the case. Although ICOT has reached its technological goals, the applications it has developed were sufficient to demonstrate the practicality of the approach, but not its conclusive superiority.
Lessons Learned
Be aware that government-supported industrial consortia may not be able to 'read the market', particularly over the long term.
Do not confuse basic research and advanced development.
Expect negative results but hope for positive. Mid-course corrections are a good thing.
Have vision. The vision is critical: people need a big dream to make it worthwhile to get up in the morning.
Logic Programming
It certainly provided a tremendous boost to research in logic programming.
I was expecting however to see 'actual use' of some of the technology at the end of the project. There are three ways in which this could have happened.
The first way would have been to have real world applications, in user terms; only little of that can be seen at this stage, even though the efforts to develop demonstrations are not be underestimated.
The second would have been to the benefit of computer systems themselves. This does not appear to be directly happening, at least not now and this is disappointing if only because the Japanese manufacturers have been involved in the FGCS project, at least as providers of human resources and as subcontractors.
The third way would have been to impact computer science outside of the direct field in which this research takes place: for example to impact AI, to impact software engineering, etc.; not a lot can yet be seen, but there are promising signs.
I am genuinely impressed by the scientific achievements of this remarkable project. For the first time in our field, there is a uniform approach to both hardware and software design through a single language, viz. KL1.
It is nearly unbelievable how much software was produced in about two and a half years written directly or indirectly in KL1.
There are at least three aspects to what has been achieved in KLI:
First the language itself is an interesting parallel programming language. KL1 bridges the abstraction gap between parallel hardware and knowledge based application programs. Also it is a language designed to support symbolic (as opposed to strictly numeric) parallel processing. It is an extended logic programming language which includes features needed for realistic programming (such as arrays).
However, it should also be pointed out that like many other logic programming languages, KL1 will seem awkward to some and impoverished to others.
Second is the development of a body of optimization technology for such languages. Efficient implementation of a language such as KL1 required a whole new body of compiler optimization technology.
The third achievement is noticing where hardware can play a significant role in supporting the language implementation.
By Companies
The main Companies involved in the project were Fujitsu, Hitachi, Mitsubishi Electric, NEC, Oki, Toshiba, Matsushita Electric Industrial and Sharp.
Almost all companies we interviewed said that ICOT's work had little direct relevance to them.
The reasons most frequently cited were: The high cost of the ICOT hardware, the choice of Prolog as a language and the concentration on parallelism.
However, nearly as often our hosts cited the indirect effect of ICOT: the establishment of a national project with a focus on 'fifth generation technology' had attracted a great deal of attention for Artificial Intelligence and knowledge based technology.
Several sites commented on the fact that this had attracted better people into the field and lent an aura of respectability to what had been previously regarded as esoteric.
Hardware
During the first 3 year phase of the project, the Personal Sequential Inference machine (PSI 1) was built and a reasonably rich programming environment was developed for it.
Like the MIT machine, PSI was a microprogrammed processor designed to support a symbolic processing language. The symbolic processing language played the role of a broad spectrum 'Kernel language' for the machine, spanning the range from low level operating system details up to application software. The hardware and its microcode were designed to execute the kernel language with high efficiency. The machine was a reasonably high performance work station with good graphics, networking and a sophisticated programming environment. What made PSI different was the choice of language family. Unlike more conventional machines which are oriented toward numeric processing or the MIT machine which was oriented towards LISP the language chosen for PSI was Prolog.
The choice of a logic programming framework for the kernel language was a radical one since there had been essentially no experience anywhere with using logic programming as a framework for the implementation of core system functions.
Several hundred PSI machines were built and installed at ICOT and collaborating facilities; and the machine was also sold commercially. However, even compared to specialized Lisp hardware in the US, the PSI machines were impractically expensive. The PSI (and other ICOT) machines had many features whose purpose was to support experimentation and whose cost/benefit tradeoff had not been evaluated as part of the design; the machines were inherently non-commercial.
The second 3 year phase saw the development of the PSI 2 machine which provided a significant speedup over PSI 1. Towards the end of Phase 2 a parallel machine (the Multi-PSI) was constructed to allow experimentation with the FGHC paradigm. This consisted of an 8 × 8 mesh of PSI 2 processors, running the ICOT Flat Guarded Horn Clause language KL1.
The abstract model of all PIMs consists of a loosely coupled network connecting clusters of tightly coupled processors. Each cluster is, in effect, a shared memory multiprocessor; the processors in the cluster share a memory bus and implement a cache coherency protocol. Three of the PIMs are massively parallel machines.
Multi-Psi is a medium scale machine built by connecting 64 Psi's in a mesh architecture.
Even granting that special architectural features of the PIM processor chips may lead to a significant speedup (say a factor of 3 to be very generous), these chips are disappointing compared to the commercial state of the art.
Specialized Hardware
Another most important issue, of a completely different nature, is the question of whether ICOT was wise to concentrate so much effort on building specialised hardware for logic programming, as opposed to building, or using off the shelf, more general purpose hardware not targeted at any particular language or programming paradigm. The problems with designing specialised experimental hardware is that any performance advantage that can be gained is likely to be rapidly overtaken by the ever-continuing rapid advance of commercially available machines, both sequential and parallel. ICOT's PSI machines are now equalled if not bettered for Prolog and CCL performance by advanced RISC processors.
Many are skeptical about the need for special purpose processors and language dedicated machines. The LISP machines failed because LISP was as fast, or nearly as fast, implemented via a good compiler on a general purpose machine. The PSI machines surely do not have a market because the latest Prolog compilers, compiling down to RISC instructions and using abstract interpretation to help optimize the code, deliver comparable performance.
It is interesting to compare the PIMs to Thinking Machines Inc.'s CM-5; this is a massively parallel machine which is a descendant of the MIT Connection Machine project. The CM-5 is the third commercial machine in this line of development.
Although the Connection Machine project and ICOT started at about the same time, the CM-5 is commercially available and has found a market within which it is cost effective.
Demo Applications
I think that this was the result of the applications being developed in an artificial set-up. I believe applications should be developed by people who need them, and in the context where they are needed.
In general, I believe that too little emphasis was placed on building the best versions of applications on the machines (as opposed to demonstration versions).
In a nutshell, the following has been achieved: for a number of complicated applications in quite diverse areas, ranging from Molecular Biology to Law it has been shown that it is indeed possible to exploit the techniques of (adapted) logic programming, LP, to formulate the problems and to use the FGCS machines to solve them in a scalable way; that is parallelism could indeed profitably be used.
The demonstrations involved:
A Diagnostic and control expert system based on a plant model
Experimental adaptive model-based diagnostic system
Case-based circuit design support system
Co-HLEX: Experimental parallel hierarchical recursive layout system
Parallel cell placement experimental system
High level synthesis system
Co-LODEX: A cooperative logic design expert system
Parallel LSI router
Parallel logic simulator
Protein sequence analysis program
Model generation theorem prover: MGTP
Parallel database management system: Kappa-P
Knowledge representation language: QUIXOTE
A parallel legal reasoning system: HELIC-II
Experimental motif extraction system
MENDELS ZONE: A concurrent program development system
Parallel constraint logic programming system: GDCC
Experimental system for argument text generation: Dulcinea
A parallel cooperative natural language processing system: Laputa
An experimental discourse structure analyzers
They have some real success on a technical level, but haven't produced applications that will make a difference (on the world market).
Programming Languages
Two extended Prolog-like languages (ESP and KL0) were developed for PSI-1. ESP (Extended Self Contained Prolog) included a variety of features such as coroutining constructs, non-local cuts, etc. necessary to support system programming tasks as well as more advanced Logic Programming. SIMPOS, the operating system for the PSI machines, was written in ESP.
Phase 3 has been centered around the refinement of the KL1 model and the development of massively parallel hardware systems to execute it.
KL1 had been refined into a three level language:
KLI-b is the machine level language underlying the other layers
KLI-c is the core language used to write most software; it extends the basic FGHC paradigm with a variety of useful features such as a macro language
KLI-p includes the 'pragmas' for controlling the implementation of the parallelism
Much of the current software is written in higher level languages embedded in KL1, particularly languages which establish an object orientation. Two such languages have been designed: A'UM and AYA. Objects are modeled as processes communicating with one another through message streams.
Two languages of this type developed at ICOT are CAL (Constraint Avec Logique) which is a sequential constraint logic programming language which includes algebraic, Boolean, set and linear constraint solvers.
A second language, GDCC (Guarded Definite Clauses with Constraints) is a parallel constraint logic programming language with algebraic, Boolean, linear and integer parallel constraint solvers.
Prolog vs LISP
Achieving such revolutionary goals would seem to require revolutionary techniques. Conventional programming languages, particularly those common in the late 1970s and early 1980s offered little leverage.
The requirements clearly suggested the use of a rich, symbolic programming language capable of supporting a broad spectrum of programming styles.
Two candidates existed: LISP which was the mainstream language of the US Artificial Intelligence community and Prolog which had a dedicated following in Europe.
LISP had been used extensively as a systems programming language and had a tradition of carrying with it a featureful programming environment; it also had already become a large and somewhat messy system. Prolog, in contrast, was small and clean, but lacked any experience as an implementation language for operating systems or programming environments.
OS
Multi-PSI supported the development of the ICOT parallel operating system (PIMOS) and some initial small scale parallel application development. PIMOS is a parallel operating system written in KL1; it provides parallel garbage collection algorithms, algorithms to control task distribution and communication, a parallel file system, etc.
AI
Interest in AI (artificial intelligence) boomed around the time and companies started to realize the potential value of FGCS research as a complement to their own AI research.
Databases
In the area of databases, ICOT has developed a parallel database system called Kappa-P. This is a 'nested relational' database system based on an earlier ICOT system called Kappa. Kappa-P is a parallel version of Kappa, re-implemented in KL1.
It also adopts a distributed database framework to take advantage of the ability of the PIM machines to attach disk drives to many of the processing elements. Quixote is a Knowledge Representation language built on top of Kappa-P.
It is a constraint logic programming language with object-orientation features such as object identity, complex objects described by the decomposition into attributes and values, encapsulation, type hierarchy and methods. ICOT also describes Quixote as a Deductive Object Oriented Database (DOOD).
Theorem Proving
Another area explored is that of Automatic Theorem Proving. ICOT has developed a parallel theorem prover called MGTP (Model Generation Theorem Prover).
Fun Trivia
The one commercial use we saw of the PSI machines was at Japan Air Lines, where the PSI-II machines were employed; ironically, they were remicrocoded as Lisp Machines.
Sources
Overview to the Fifth Generation Computer System project (1983)
The Japanese national Fifth Generation project: introduction, survey, and evaluation (1993)
An overview and appraisal of the Fifth Generation Computer System project (1993)
Conclusion
This section has no quotes from sources, these are my observations:
I find that for every thing you can point as a reason for its "failure" there's an alternative universe where you could point to the same things as reasons for its success.
For example:
Starting from scratch
Thinking from first principles
Radical changes to the status quo
Single focus
Vertical integration
Risky bet on nascent technologies
Specialized Hardware
The only reason that is clearly negative is that the demo applications were not developed with real use cases and involving real users, that may have made it harder to show the value of FGCS to end users and industrial partners.
It would be easy to mention Worse is Better but if it keeps coming up as a reason, maybe we should pay more attention to it?
My conclusion right now is that technically they achieved many of the things they planned, they succeeded at going where they thought the puck was going to be in the 90s but it ended up somewhere else.
What's your conclusion?